Run Highly Efficient and Accurate AI Agents with NVIDIA Nemotron 3 Nano on vLLM
We are excited to release the NVIDIA Nemotron 3 Nano, supported by vLLM.
Nemotron 3 Nano is part of the newly announced Nemotron 3 family of most efficient open models with leading accuracy for building agentic AI applications. The Nemotron 3 family of models use a hybrid Mamba-Transformer MoE architecture and 1M token context length. This enables developers to build reliable, high-throughput agents across complex, multi-document, and long-duration operations.
Nemotron 3 Nano is fully open with open-weights, datasets and recipes so developers can easily customize, optimize, and deploy the model on their infrastructure for maximum privacy and security. The chart below shows that Nemotron 3 Nano leads is in the most attractive quadrant in Artificial Analysis Openness vs Intelligence Index
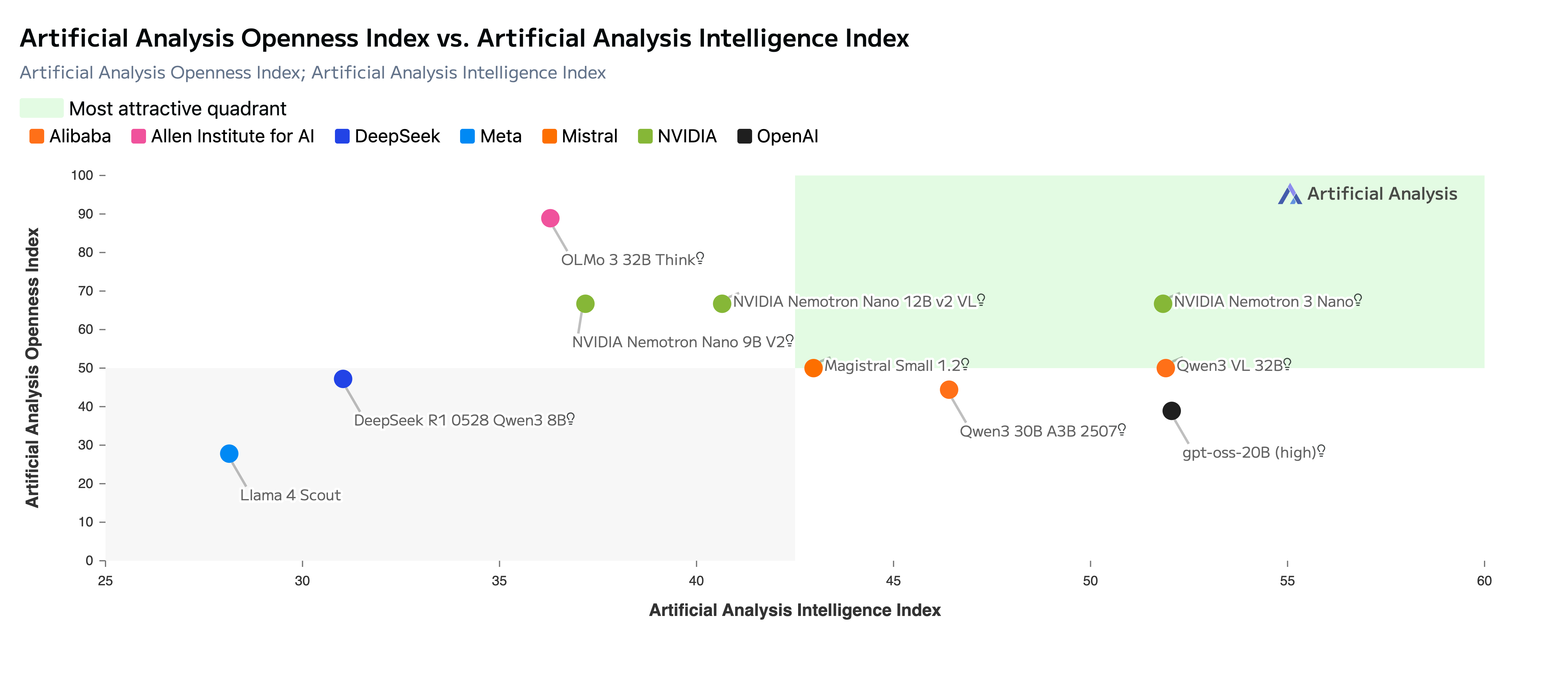
Figure 1: NVIDIA Nemotron 3 Sets a New Standard for Open Source AI
Nemotron 3 Nano excels in coding, reasoning, and agentic tasks, and leads on benchmarks such as SWE Bench Verified, GPQA Diamond, AIME 2025, Arena Hard v2, and IFBench.
In this blog post, we’ll share how to get started with Nemotron 3 Nano using vLLM for inference to unlock high-efficiency AI agents at scale.
About Nemotron 3 Nano
- Architecture:
- Mixture of Experts (MoE) with Hybrid Transformer-Mamba Architecture
- Supports Thinking Budget for providing optimal accuracy with minimum reasoning token generation
- Accuracy
- Leading accuracy on coding, scientific reasoning, problem solving, math, instruction following, chat
- Model size: 30B with 3B active parameters
- Context length: 1M
- Model input: Text
- Model output: Text
- Supported GPUs: NVIDIA RTX Pro 6000, DGX Spark, H100, B200.
- Get started:
- Download model weights from Hugging Face - BF16, FP8
- Run with vLLM for inference
- Technical report to build custom, optimized models with Nemotron techniques.
Run optimized inference with vLLM
Nemotron 3 Nano, achieves accelerated inference and serves more requests on the same GPU with BF16, FP8 precision support. Follow these instructions to get started:
Run the command below to install vLLM.
VLLM_USE_PRECOMPILED=1 pip install git+https://github.com/vllm-project/vllm.git@main
We can then serve this model via an OpenAI-compatible API
export VLLM_ATTENTION_BACKEND=FLASHINFER
# BF16
```bash
vllm serve --model "nvidia/NVIDIA-Nemotron-Nano-3-30B-A3B-BF16" \
--dtype auto \
--trust-remote-code \
--served-model-name nemotron \
--host 0.0.0.0 \
--port 5000 \
--enable-auto-tool-choice \
--tool-call-parser qwen3_coder \
--reasoning-parser deepseek_r1
```
OR
```bash
python -m vllm.entrypoints.openai.api_server \
--model "nvidia/NVIDIA-Nemotron-Nano-3-30B-A3B-BF16" \
--dtype auto \
--trust-remote-code \
--served-model-name nemotron \
--host 0.0.0.0 \
--port 5000 \
--enable-auto-tool-choice \
--tool-call-parser qwen3_coder \
--reasoning-parser deepseek_r1
```
# Swap out model name for FP8
```bash
vllm serve --model "nvidia/NVIDIA-Nemotron-Nano-3-30B-A3B-FP8" \
--dtype auto \
--trust-remote-code \
--served-model-name nemotron \
--host 0.0.0.0 \
--port 5000 \
--enable-auto-tool-choice \
--tool-call-parser qwen3_coder \
--reasoning_parser deepseek_r1
```
Once the server is up and running, you can prompt the model using the below code snippets
from openai import OpenAI
client = OpenAI(base_url="http://127.0.0.1:5000/v1", api_key="null")
# Simple chat completion
resp = client.chat.completions.create(
model="nemotron",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Write a haiku about GPUs."}
],
temperature=0.7,
max_tokens=256,
)
print(resp.choices[0].message.reasoning_content, resp.choices[0].message.content)
For an easier setup with vLLM, refer to our getting started cookbook, available here.
Highly efficient with leading accuracy for agentic tasks
Nemotron 3 Nano builds upon the hybrid Mamba-Transformer architecture of our Nemotron Nano 2 models by replacing the standard feed forward network (FFN) layers with sparse MoE layers and most of the attention layers with Mamba-2. The MoE layers help us achieve better accuracy at a fraction of the active parameter count. With MoE architecture, Nemotron 3 Nano reduces compute requirements and meets the stringent latency requirements of real-world applications.
With hybrid Mamba-Transformer architecture, Nemotron 3 Nano delivers up to 4x higher token throughput, enabling the model to think faster and provide higher accuracy simultaneously. The “thinking budget” feature prevents the model from overthinking and optimizes for a lower, predictable inference cost.

Figure 2: Nemotron 3 Nano delivers higher throughput and leading accuracy among open reasoning models
Trained on NVIDIA-curated, high-quality data, Nemotron 3 Nano leads on benchmarks such as SWE Bench Verified, GPQA Diamond, AIME 2025, Arena Hard v2, and IFBench delivering top-tier accuracy in coding, reasoning, math and instruction following. This makes it ideal for building AI agents for various enterprise use cases including finance, cybersecurity, software development and retail.
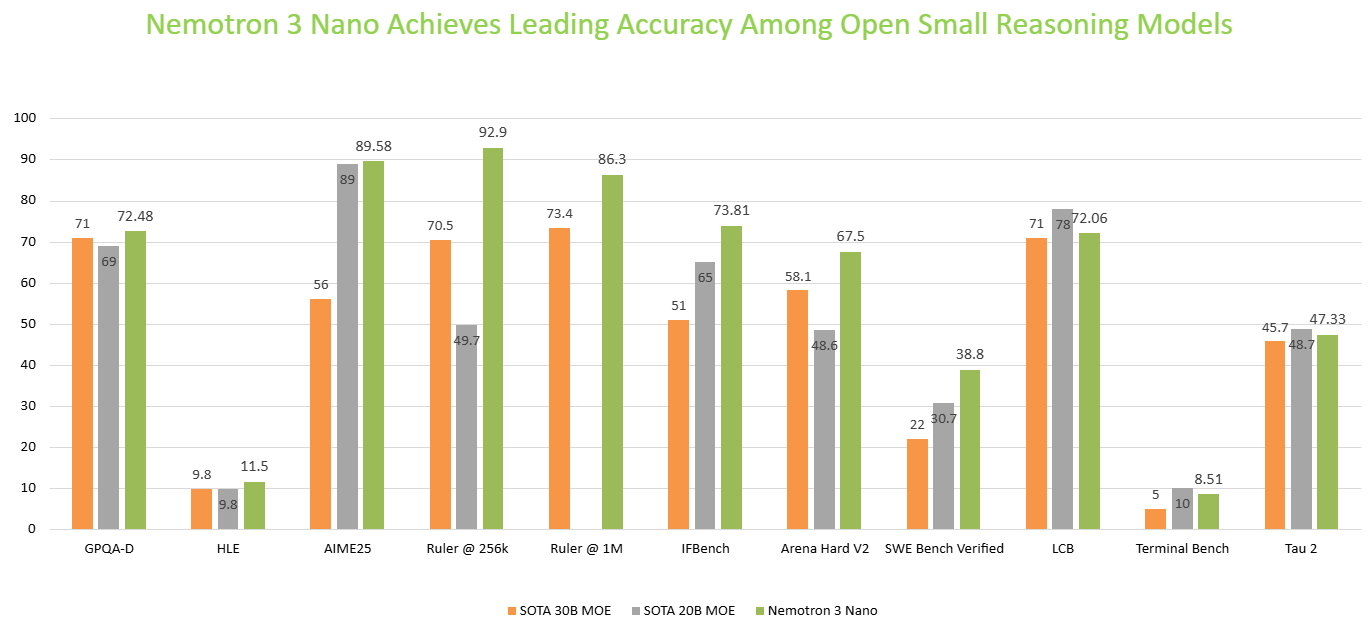
Figure 3: Nemotron 3 Nano provides leading accuracy on various popular academic benchmarks among open small reasoning models
Get Started
To summarize, Nemotron 3 Nano helps build scalable, cost-efficient agentic AI systems in various industries. With open weights, training datasets, and recipes, developers gain full transparency and flexibility to fine-tune and deploy the model across any environment, from on-premise to cloud, for maximum security and privacy.
Ready to build enterprise-ready agents?
- Download Nemotron 3 Nano model weights from Hugging Face - BF16, FP8
- Run with vLLM for inference using this cookbook
Share your ideas and vote on what matters to help shape the future of Nemotron.
Stay up to date on NVIDIA Nemotron by subscribing to NVIDIA news and following NVIDIA AI on LinkedIn, X, YouTube, and the Nemotron channel on Discord.